내용
그래픽_plot()과 산점도
개요
R에서 그래프를 작성하는 함수는 고수준(high-level)과 저수준(low-level) 함수로 구분합니다. 고수준 함수는 새로운 그래프를 시작하며 축적, 제목과 라벨, 장식 등을 첨가할 수 있습니다. 반면에 저수준 함수는 새로운 그래프를 시작할 수 없으며 고수준 함수에 의해 생성된 그래프에 점, 선, 텍스트, 장식 등을 추가합니다.
| 고수준 함수 | 설명 | 저수준함수 | 설명 |
|---|---|---|---|
| plot | 제네릭(generic) 그래프 함수 | points | 점을 추가 |
| boxplot | 박스플롯 생성 | lines | 선을 추가 |
| hist | 히스토그램 생성 | abline | 직선을 추가 |
| qqnorn | Q-Q 플롯을 생성 | segments | 선분을 추가 |
| curve | 함수를 그래프로 작성 | polygon | 닫힌 다각형을 추가 |
| coplot | 조건화그래프 | text | 텍스트를 추가 |
| barplot | 막대그래프 |
새로운 그래프를 작성하기 위해서는 고수준함수를 호출한 후 저수준 함수를 작성합니다.
고수준 함수인 plot(x)은 전달하는 인자 x에 따라 생성되는 그래프 형상이 달라집니다. 즉, x가 벡터, 요인, 데이터프레임에 따라, 선형회귀 모형, 도수분포표 또는 다른 타입의 형태에 따라 다른 그래프를 생성합니다. 이것은 다형성(polymorphism)이라고 합니다. 그러므로 제네릭함수인 plot을 다형함수라고 합니다.
plot(): 산점도
두 열(column)로 으로 구성된 자료에 대해 plot()함수를 작성합니다. 데이터 cars는 두개의 열로 구성된 데이터 프레임입니다. 이 데이터를 인수로 전달하는 경우 순서대로 (x, y)인수로 대응됩니다.
cars%>%sample_n(size=3)
speed dist 1 18 56 2 12 20 3 7 4
class(cars)
[1] "data.frame"
plot(cars, main="Speed vs Distance", xlab="speed(MPH)", ylab="dist(ft)") grid()

위 코드는 다음과 같습니다.
plot(cars$speed, cars$dist, ...)
두 개이상의 열로 구성된 데이터 프레임의 경우 여러 개의 산점도를 생성합니다. 산점도를 작성하기 위해서는 데이터는 수치형(numeric)이어야 하며 수치형이 아닌 경우 다른 그래프가 생성됩니다.
제목과 라벨
plot()함수에 제목과 라벨을 추가하기 위한 인수는 다음과 같습니다.
- 제목: main=" "
- x축 라벨: xlab=" "
- y축 라벨: ylab=" "
다른 방법으로는 ann=FALSE(주석 금지)의 인수를 첨가하고 title()함수에 제목과 라벨을 추가합니다.
plot(cars, ann=FALSE) Title(main=" ", xlab=" ", ylab=" ")
격자 추가
그래픽 생성후에 grid()함수를 호출합니다. 또한 plot()함수에 인수 type=n 을 첨가하여 데이터를 제거한 후 points()등의 저수준함수를 호출합니다.
plot(x, ...) grid()또는
plot(x, ..., type=n) grid() points()
여러개 산점도 작성
다음 데이터는 data.frame 형식으로 여러개의 열로 구성됩니다. 이러한 형태의 자료의 산점도를 작성하면 각 두 열의 산점도들로 구성된 그래프 행렬이 생성됩니다.
iris%>%sample_n_by(Species, size=1)
# A tibble: 3 × 5 Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5 3.2 1.2 0.2 setosa 2 6.7 3 5 1.7 versicolor 3 7.1 3 5.9 2.1 virginica
plot(iris)

위 자료는 열 Species는 factor형입니다. 즉, 다른 값들은 Species의 레벨에 의해 그룹화됩니다. 에를 들어 Spel.Length와 Sepal.Width를 Species의 레벨에 따라 구별하기 위해 plot()함수의 col 또는 pch 인자를 사용합니다. col은 color, pch 인자는 그래프의 mark의 형태를 지정하기 위한 인수로서 전달되는 값은 0을 포함한 양의 정수입니다.(help() 참조)
attributes(iris$Species)$levels
[1] "setosa" "versicolor" "virginica"
위와 같이 Species는 3개의 레벨로 구성되어 있으며 문자열(string)입니다. 이들을 수치형으로 전환하기 위해 as.integer() 함수를 적용합니다.
as.integer(iris$Species)
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...
with(iris, plot(Petal.Length, Petal.Width, pch=as.integer(Species)))

범례(legend)
legend()함수를 추가합니다.
legend(x, y, legend, method, border, bty)
- x, y: 범례의 위치를 지정
- legend: 범례에 표시될 라벨
- method: 라벨을 구분하는 형식에 따라 달라짐
- 점: pch=c(점유형1, 점유형2, ...)
- 선 스타일: lty=c(선스타일1, 선스타일2, ...)
- 선 두께: lwd=c(선두께1, 선두께2, ...)
- 색상: 내부색 지정, fill=c(색상1, 색상2, ...)
- border: 테두리 색 선택
- bty="n": 범레박스의 테두리 선을 제거
위 megthod는 legend에 대응하여 작성됩니다. 즉, 이 두 인자는 같이 작성하여야 합니다.
with(iris, plot(Petal.Length, Petal.Width, col=as.integer(Species)))
legend(1, 2.4, c("setosa", "versicolor", "virginica"), fill=c('black', 'red', 'green') , border=FALSE)

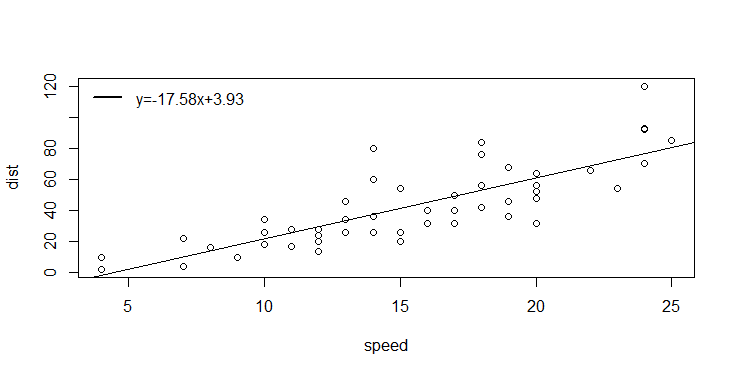
산점도에 회귀선 추가
plot(x, y) 함수에 의해 생성된 그래프에 abline(m) 함수를 추가합니다. 이 경우 인수 m은 lm() 모델입니다. 또한 전달하는 데이터 (x, y)는 (y~x)와 같이 formula 형태일 수 있습니다.
plot() 함수에 data 또는 formula 대신에 모델 m을 전달할 경우(plot(m))의 경우 회귀모형의 4개의 진단 그래프들을 작성하는 것으로 일반적으로 사용하는 plot()의 결과와는 다릅니다.
m<-lm(dist~speed, data=cars)
with(cars, plot(dist~speed))
abline(m)
legend("topleft", "y=-17.58x+3.93", lwd=2, bty="n")
요인의 수준에 따른 산점도의 분리
두개의 수치형 변수들이 요인(factor)의 인수에 따라 별도의 그래프를 작성하기 위해서는 조건화그래프(conditioning plot)을 사용합니다.
coplot(y~x | factor)
with(iris, coplot(Sepal.Width~Sepal.Length| Species)

선그래프
산점도를 작성하는 plot() 함수를 사용하여 선 그래프를 작성할 경우 매개변수 type="l"을 첨가합니다. 다음은 R 내장 data인 pressure를 사용합니다.
colnames(pressure)
[1] "temperature" "pressure"
par(mfrow=c(1,2)) plot(pressure, main="Scatter of Dataset Pressure") plot(pressure, type="l", main="Line of Dataset Pressure")

선 그래프의 선의 유형, 두께, 색상은 매개변수 lty, lwd, col을 사용하여 변경할 수 있습니다. 다음은 선 유형을 지정하는 값입니다.
| 명령 | 선유형 | |
|---|---|---|
| lty="solid" | lty=1 | 실선(기본값) |
| lty="dashed" | lty=2 | 대시선 |
| lty="dotted" | lty=3 | 점선 |
| lty="dotdash" | lty=4 | 점 대시선 |
| lty="longdash" | lty=5 | 긴 대시선 |
| lty="twodash" | lty=6 | 이중 대시선 |
| lty="blank" | lty=0 | 선없음 |
plot(pressure, type="l", lty=2, lwd=2, col="blue") plot(pressure, type="l", lty=3, lwd=1, col="red")

한 그래프에 여러개의 선을 표시하기 위해서 저수준 함수를 첨가합니다.
다음에 사용된 데이터의 경우 y1과 y2의 범위가 다릅니다. 이 경우 각 축의 스케일은 고수준 함수인 plot()을 따르기 때문에 다음의 왼쪽 그림과 같이 일부는 소실됩니다. 이것은 각 축의 범위를 지정하는 xlim, ylim을 지정함으로서 방지할 수 있습니다.
x<-1:10 y1<-sort(sample(1:15, 10)) y2<-sort(sample(5:50, 10)) par(mfrow=c(1,2)) plot(x, y1, type="l", ylab="y", col="blue") lines(x, y2, col="red") plot(x, y1, type="l", ylab="y", ylim=c(0, 51), col="blue") lines(x, y2, col="red")

댓글
댓글 쓰기